No Lotus Notes/Domino developer wants to hear the following comment: "Beautiful application, too bad it's so slow!" In this two-part article series, we explain how you can avoid this embarrassment by building Notes/Domino applications optimized for performance.
One of the saddest sights we know is a beautiful application that is so slow it's unusable -- all the long hours and hard work wasted because users are frustrated by slow response times. Over the past 12 years, we've spent a lot of time researching and testing Domino applications and functionality to understand how and where features can best be used to optimize performance. We started supporting and developing Domino applications in the early 1990s, and quickly became fascinated with application performance. It seemed to us then (as it still does today) that much of what we perceive as server performance problems are actually application performance problems. And the solutions, therefore, are often found within the application rather than on the server.
In this two-part article series, we will share some of what we've learned with you. This series covers three areas of application performance: database properties, document collections, and views. In part 1, we will discuss database properties and document collections. In each case, we will point out areas that are most significant and provide concise, real-world examples to help you understand what to do in your own applications. We'll use examples from many applications; you'll probably find that at least one of them closely matches something that you do or that you use. Our goal is to help you build applications that are as fast as they are beautiful.
This article assumes that you're an experienced Notes/Domino application developer.
Database properties
There are a handful of database properties that are relevant to the performance of your application.
Don't maintain unread marks
If you check this box, unread marks will not be tracked in your application regardless of the settings you have for each view. We used client_clock to track the time spent opening a database, and what we saw surprised us. For a large application (say 20 GB with 200,000 documents), our Notes client could open the database in about five seconds without unread marks, including network traffic. With unread marks turned on, we had to wait an additional six seconds or more. This additional time was spent in GET_UNREAD_NOTE_TABLE and RCV_UNREAD. With unread marks turned off, these calls aren't made.
In a smaller database (less than 1 GB), we saw savings of maybe 0.5 seconds with unread marks turned off. Of course, it was faster to open that database with or without unread marks compared to the larger database. So you should consider whether or not your application needs the unread marks feature before you roll it out into production.
Optimize document table map
This feature has not changed for the past few releases of Lotus Notes/Domino. This feature is designed to speed up view indexing for applications with structures that resemble the Domino Directory. (In other words, they contain many documents that use one form and a small number of documents using a different form. Think of Person documents versus Server documents in the Domino Directory.)
The idea is that, instead of checking every document note to see whether or not it should be included in a view index, we make two passes. The first pass merely checks to see if the correct form name is associated with that document. The second pass, if needed, checks for the various other conditions that must be met to include this document note in the view index.
Note: Currently, this feature does not appear to improve indexing times, not even for Domino Directories.
Don't overwrite free space
This feature has not changed for the past few releases of Lotus Notes/Domino. If you uncheck this box, then whenever documents are deleted, Lotus Notes will actually overwrite the bits of data instead of merely deleting the pointer to that data. The goal is to make the data unrecoverable. You would only use this feature if you feared for the physical safety of your hard disk. For virtually every application, this extra physical security is unwarranted and is merely an extra step when data is deleted.
Maintain LastAccessed property
This feature has not changed for the past few releases of Lotus Notes/Domino. If you check this box, Notes will track the last time a Notes client opened each document in the database. Lotus Notes always tracks the last save, of course, in the $UpdatedBy field, but this feature tracks the last read as well. (It does not track Web browser reads, however.)
We have not seen this feature used by developers other than in knowledge base applications, where data is archived if it has not been read within a certain number of months or years.
Document collections
We've looked at customer code for many years in agents, in views, in form field formulas, and so on. In our experience, frontend performance problems tend to be more troublesome than backend performance problems for a number of reasons:
1-backend processes are typically monitored more rigorously.
2-backend processes frequently do not have to worry about network traffic.
3-frontend problems can be confusing to decipher. Users often are not sure which actions are relevant, causing them to report unimportant and even unrelated actions to your Support desk.
But regardless of where the code comes from, if we find that something is slow and we open up the code to examine it, we will likely find the following as a common denominator:
1- The code establishes certain criteria from context, such as user's name, status of document that user is in, today's date, and so on.
2- The code gets a collection of documents from this or another database.
3- The code reads from, and/or writes to, these documents.
From performing tests over many years, we have found that typically, the first step is very fast and not worth optimizing, at least not until bigger battles have been fought and won. The third step is often slow, but unfortunately it is not very elastic. That is, you are unlikely to find that your code is inefficiently reading information from or saving information to a set of documents. For example, if you are trying to save today's date to a field called DateToday, you would likely use one of the following methods:
Extended class
Set Doc = dc.getfirstdocument
Do while not (Doc is Nothing)
Doc.DateToday = Today
Call Doc.Save
Set Doc = dc.getnextdocument ( Doc )
Loop
ReplaceItemValue
Set Doc = dc.getfirstdocument
Do while not (Doc is Nothing)
Call Doc.ReplaceItemValue ("DateToday", Today)
Call Doc.Save
Set Doc = dc.getnextdocument (Doc)
Loop
StampAll
Call dc.StampAll ("TodayDate", Today)
In our testing, we've never found a difference in performance between the first two of the three preceding examples. Using the extended class syntax, doc.DateToday = Today, appears to be just as fast as using doc.ReplaceItemValue ("DateToday", Today). In theory, we should see some performance difference because in one case, we are not explicitly telling Lotus Notes that we will update a field item, so Lotus Notes should spend a bit longer figuring out that DateToday is, in fact, a field. However, practical tests show no difference.
The dc.StampAll method is faster if you are updating many documents with a single value as in the preceding example. There were some point releases in which a bug made this method much slower, so if you're not using the latest and greatest, please confirm this is working optimally (either with testing or by checking the fix list). But as of Lotus Notes/Domino 6.5 and 7, this is once again fast. However, there are often so many checks to perform against the data or variable data to write to the documents that dc.StampAll is not always a viable option. We would put it into the category of a valuable piece of information that you may or may not be able to use in a particular application.
As for deciding which of the three methods we should focus on, our experience says that the ReplaceItemValue example (getting a collection of documents) is the one. It turns out that this is often, by far, the largest chunk of time used by code and fortunately, the most compressible. This was the focus of oiur testing and will be discussed in the remainder of this section.
Testing
Our testing methodology was to create a large database with documents of fairly consistent size (roughly 2K) and with the same number of fields (approximately 200). We made sure that the documents had some carefully programmed differences, so that we could perform lookups against any number of documents. Specifically, we made sure that we could do a lookup against 1, 2, 3, … 9, 10 documents; and also 20, 30, 40, … 90, 100; and also 200, 300, 400, … 900, 1000; and so on. This gave us a tremendous number of data points and allowed us to verify that we were not seeing good performance across only a narrow band. For example, db.search is an excellent performer against a large subset of documents in a database, but a poor performer against a small subset. Without carefully testing against the entire spectrum, we might have been misled as to its performance characteristics.
We ran tests for many hours at a time, writing out the results to text files which we would then import into spreadsheets and presentation programs for the purpose of charting XY plots. After many such iterations and after trying databases that were small (10K documents) and large (4 million documents), we came up with a set of guidelines that we think are helpful to the application developer.
Which methods are the fastest?
The fastest way to get a collection of documents for reading or writing is to use either db.ftsearch or view.GetAllDocumentsByKey. It turns out that other methods (see the following list) may be close for some sets of documents (discussed later in this article), but nothing else can match these methods for both small and large collections. We list the methods with a brief explanation here and go into more detail later.
1- view.GetAllDocumentsByKey gets a collection of documents based upon a key in a view, then iterates through that collection using set doc = dc.GetNextDocument (doc).
2- db.ftsearch gets a collection of documents based upon full-text search criteria in a database, then iterates through that collection using set doc = dc.GetNextDocument (doc).
3- view.ftsearch gets a collection of documents based upon full-text search criteria, but constrains the results to documents that already appear in a view. It then iterates through the collection using set doc = dc.GetNextDocument (doc).
4- db.search gets a collection of documents based upon a non-full-text search of documents in a database, then iterates through the collection using set doc = dc.GetNextDocument (doc).
5- view.GetAllEntriesByKey gets a collection of view entries in a view, then either reads directly from column values or gets a handle to the backend document through the view entry. It then iterates through the collection using set entry = nvc.GetNextEntry (entry).
If you have a small collection of documents (for example, 10 or so) and a small database (for instance, 10,000 documents), many different methods will yield approximately the same performance, and they'll all be very fast. This is what you would call the trivial case, and unless this code is looping many times (or is used frequently in your application), you might leave this code intact and move on to bigger problems.
However, you still may find small differences, and if you need to get many collections of documents, then even saving a fraction of a second each time your code runs will become meaningful. Additionally, if your application is large (or growing), you'll find the time differences can become substantial.
Here are two customer examples: first, scheduled agents that are set to run very frequently (every few minutes or whenever documents have been saved or modified) that iterate through every new document to get search criteria, and then perform searches based on that criteria. If 10 new documents were being processed, then 10 searches were performed -- and if 100 new documents were processed, then 100 searches were performed. For this customer, if we could shave 0.5 second off the time to get a collection of documents, that savings was really multiplied by 10 or 100, and then multiplied again by the frequency of the execution of the agent. It could easily save many minutes per hour during busy traffic times of the day, which is meaningful. Another case is a principal form has a PostOpen or QuerySave event that runs this code. If you have hundreds of edits per hour (or more), this 0.5 second saved will be multiplied to become a noticeable savings.
Pros and cons of each method
When we explained to colleagues or customers why some of these methods are faster or easier to use than other methods, we often engaged in a spirited debate, complete with "on the one hand" and "on the other hand" arguments. To our great satisfaction, the deeper we've taken these arguments, the clearer the issues have become. We will attempt to invoke that same spirit in this article with two mythical debating opponents, Prometheus ("Pro" to his friends) and his skeptical colleague Connie (a.k.a "Con").
Prometheus: view.GetAllDocumentsByKey looks very fast. I think I'm sold on using it wherever I can.
Connie: All well and good, my friend, but what if you're looking up data in the Domino Directory? You can't get permission to create new views there easily.
Pro: Great point. OK, in applications where I control the lookup database, that's where I'll use this method.
Con: Oh? And if you end up creating an additional 10 views in that database, is it still a good method? Think of all the additional view indexing required.
Pro: That might appear to be a nuisance, but if I build streamlined views, they will likely index in less than 100 milliseconds every 15 minutes when the UPDATE task runs -- more if required by lookups. Surely we can spare a few hundred milliseconds every few minutes?
Con: How do you streamline these views? Is that hard? Will it require much upkeep?
Pro: Not at all. To streamline a lookup view, you first make the selection criteria as refined as possible. This reduces the size of the view index and therefore, the time to update the index and perform your lookup. Then, think about how you'll do your lookups against this view. If you're going to get all documents, consider simply using a single sorted column with a formula of "1." Then it's trivial to get all the documents in the view. If you need many different fields of information, consider making a second column that concatenates those data points into a single lookup. One lookup is much faster than several, even if the total data returned is the same.
Con: OK, I might be sold on that method. But you have also touted db.ftsearch as being very fast, and I'm not sure I'm ready to use that method. It seems like it requires a lot of infrastructure.
Pro: It is true that to use db.ftsearch reliably in your code, you'll need to both maintain a full-text index and also make sure that your Domino server's configuration includes FT_MAX_SEARCH_RESULTS=n, where n is a number larger than the largest collection size your code will need to return. Without it, you are limited to 5,000 documents.
Con: And what happens if the full-text index isn't updated fast enough?
Pro: In that case, your code can include db.UpdateFTIndex to update the index.
Con: My testing indicates that this can be quite time consuming, far outweighing any performance benefits you get from using db.ftsearch in the first place. And what happens if the full-text index hasn't even been created?
Pro: If the database has fewer than 5,000 documents, a temporary full-text index will be created on-the-fly for you.
Con: I have two problems with that. First, a temporary full-text index is very inefficient because it gets dumped after my code runs. Second, 5,000 documents isn't a very high threshold. Sounds like that would only be some mail files in my organization. What if there are more than 5,000 documents in the database?
Pro: In that case, using db.UpdateFTIndex (True) will create a permanent full-text index.
Con: OK, but creating a full-text index for a larger database can be very time consuming. I also know that the full-text index will only be created if the database is local to the code -- that is, on the same server as the code that is executing.
Pro: True enough. Fortunately, Lotus Notes/Domino 7 has some improved console logging as well as the ability to use Domino Domain Monitoring (DDM) to more closely track issues such as using ftsearch methods against databases with no full-text index. Here are a couple of messages you might see on your console log. As you can see, they are pretty clear:
Agent Manager: Full text operations on database 'xyz.nsf' which is not full text indexed. This is extremely inefficient.
mm/dd/yyyy 04:04:34 PM Full Text message: index of 10000 documents exceeds limit (5000), aborting: Maximum allowable documents exceeded for a temporary full text index
Con: While I'm at it, I see that you haven't said much positive about view.ftsearch, view.GetAllEntriesByKey, or db.search. And I think I know why. The first two are fast under some conditions, but if the view happens to be structured so that your lookup data is indexed towards the bottom, they can be very slow. And db.search tends to be very inefficient for small document collections.
Pro: All those points are true. However, db.search is very effective at time/date sensitive searches, where you would not want to build a view with time/date formulas and where you might not want to have to maintain a full-text index to use the db.ftsearch method. Also, if you are performing lookups against databases not under your control and if those databases are not already full-text indexed, it is possible that db.search is your only real option for getting a collection of documents.
Here are some charts to help quantify the preceding points made by Pro. These charts show how long it takes to simply get a collection of documents. Nothing is read from these documents and nothing is written back to them. This is a test application in our test environment, so the absolute numbers should be taken with a grain of salt. However, the relationships between the various methods should be consistent with what you would find in your own environment.
In Figure 1, db.ftsearch and view.GetAllDocumentsByKey are virtually indistinguishable from each other, both being the best performers. Call that a tie for first place. A close third would be view.GetAllEntriesByKey, while view.ftsearch starts out performing very well, but then rapidly worsens as the number of documents hits 40 or so.
Figure 1. Document collections, optimized views (up to 100 documents)
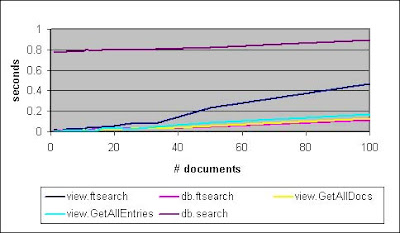
In Figure 2, the only difference worth noting from Figure 1 is that db.search looks better and better as the number of documents increases. It turns out that at approximately 5 to 10 percent of the documents in a database, db.search will be just as fast as the front runners. As we saw in Figure 1, view.ftsearch is getting worse and worse as the document collection size increases.
Figure 2. Document collections, optimized views (100 to 1,000 documents)
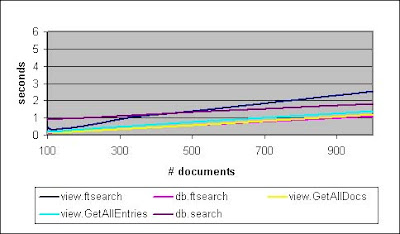
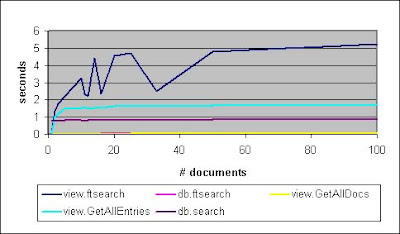
In Figure 3, the views are no longer optimized to put the results towards the top. That is, if we are getting a collection of only a few documents, then in our test environment, we can try to skew the results by making sure those few documents are towards the top or bottom of the lookup view. In Figures 1 and 2, those documents tended to be towards the top of the view, but in Figure 3, those documents are at the bottom. For three of the methods, this is immaterial (db.search, db.ftsearch, and view.GetAllDocumentsByKey). However, for view.ftsearch and view.GetAllEntriesByKey, this switch is catastrophic in terms of performance. The scale on Figures 2 and 3 had to be changed -- instead of the Y-axis going up to one second, it has to go up to six seconds!
Figure 3. Document collections, non-optimized views
Conclusion
Whenever feasible, use view.GetAllDocumentsByKey to get a collection of documents. In conjunction with this method, streamline your lookup views so that they are as small and efficient as possible. Part 2 of this article series has some tips for doing this.
If your lookups need to go against rich text fields, or if your database is already full-text indexed, db.ftsearch is an excellent performer and well worth considering. Be sure that your results will always be less than 5,000 documents or use the Notes.ini parameter FT_MAX_SEARCH_RESULTS=n (where n is the maximum number of documents that can be returned) to guarantee that you do not lose data integrity due to this limit.
Part 2: Optimizing database views
In "Lotus Notes/Domino 7 Application Performance, Part 1," we examined how you can improve the performance of Lotus Notes/Domino 7 applications through the efficient use of database properties and document collections. In part 2, we explain how you can build high-performing views. As in part 1, this article provides many code snippets that you can re-use and adapt to your own requirements.
Over many years of analyzing application performance issues, we found that views are frequently involved in both the problem and the solution. Often, view indexing is the issue. This article explains how this can happen and what you can do to troubleshoot and resolve this type of problem. But there is another kind of view performance problem that has been popping up more frequently over the past few years. This involves views that display reader access controlled documents. The performance problems seen in these views are often not indexing related, so we’ll take a little time to discuss these separately.
This article assumes that you're an experienced Notes/Domino application developer.
Understanding view indexing (the Update task)
The first thing you have to know before troubleshooting a performance problem that may involve view indexing is how the indexing process works. Indexing is typically done by the Update task, which runs every 15 minutes on the Domino server. Technically, it is possible to tune that interval, but it involves renaming files, so it is rarely done.
When the Update task runs, it looks for every database on the server with a modified date more recent than the last time the Update task ran. Then the task refreshes the views in those databases. Based on our experience, it is reasonable to assume that it takes approximately 100 milliseconds to refresh a normal view in a production database in a production environment.
The logical question to ask is, "What flags a view as needing to be updated?" Every time any of the following occurs a view requires updating:
1- Replication sends a document modification to a database
2- A user saves or deletes a document (and then exits the database)
3- The router delivers a document
The Update task is very liberal in how it determines if a view needs to be updated. For example, imagine that you’re in your mail file and that you change the BCC field of a memo and nothing else. No view displays the contents of that field, so in fact, no view needs to be refreshed. But nevertheless, views that contain this memo will at least be examined simply because the server is not sure whether or not the edits you made will force a change in those views.
There is a twist to this: Users can force an immediate high-priority request to have a view refreshed by opening the view or by being in a view when they make a document change. Let’s look at an example.
Suppose Alice opens the Contact Management database to view #1 at 9:02 AM. Suppose also that the Update task conveniently ran at 9:00:00 and will run again at 9:15:00, 9:30:00, and so on. Alice updates a couple of documents at 9:05 AM. She creates new documents, edits existing ones, or maybe deletes documents. In any case, the server immediately updates view #1 because she is in that view. It would be strange if you deleted a document and still saw it in the view, right? So that view is updated right away. But the other views are queued for updating at 9:15 AM.
Now imagine that Bob is also in our Contact Management database at 9:02 AM. He is working in view #1. At 9:05 AM, he sees the blue reload arrow in the upper left corner, telling him that the view has been updated. He can press the F9 key or click the reload arrow, and the view will quickly display the updated contents. He doesn’t have to wait for a refresh.
Further, suppose Cathy is also in the database at 9:02 AM, but working in view #2. If she does not do anything to force a refresh in the interim (which is possible, but unlikely), then she sees the blue reload arrow at 9:15 AM when her view is refreshed by the Update task. More likely, though, Cathy makes some data updates of her own, scrolls through the view enough to force an update, or switches views. Any of these actions would force an immediate update.
At 9:15 AM, all the views that these clients have not already forced to refresh are refreshed, and we start all over again.
Additional information on view indexing
There are two additional pieces of information that we find helpful. The first is the full-text indexer. Typically, full-text indexes that are marked to update immediately are updated within seconds (or minutes if the server is busy). Full-text indexes that are hourly are updated (triggered) by the Update task at the appropriate interval. Full-text indexes that are daily are updated (triggered) by the Updall task when Updall runs at night.
The second additional point is that the developer can set indexing options in the view design properties. Many people misunderstand these to be settings that affect how the Update or Updall tasks will run. This is not so. The Update and Updall tasks will completely ignore these settings, updating views based solely on the criteria described in the preceding example.
The indexing options affect what happens when a client opens a view. If the options are set to manual, for example, then the user gets a (possibly stale) version of the view very quickly. If the options are set to "Auto, at most every n hours" and if it has been more than the specified time interval, then the user will have to wait a moment while the view is updated, just as if it were a regular view with Automatic as the view indexing option. We will discuss how these indexing options can be used to help craft useful views later in this article.
Quick tips on troubleshooting view indexing
In a well-tuned environment, indexing should be relatively transparent; views and full-text indexes should be updated quickly. In an environment experiencing performance problems, you may see the following symptoms:
1- Long delays when opening a database, opening a view, switching views, scrolling through a view, or saving a document
2- Delays when opening a document that uses lookups (In fact, you may see the form pause at certain points as it waits for these lookups to compute.)
3- Performance problems throughout the working day, but excellent performance during the off-hours
4- Out-of-date full-text indexes
The following logging and debugging Notes.ini parameters can help you address these issues:
log_update=1
Writes extra information to the log.nsf Miscellaneous Events view. This consists of one line of information every time the Update task starts updating a database, and a second line when the Update task finishes with that database. Each line has a time/date stamp, so by subtracting the times, you can get an approximate time (rounded to the nearest second) required to update that database.
log_update=2
Writes more information to the log. In addition to the data generated by log_update=1, this setting adds one line of information for each view in each database. Thus, a database with 75 views would have 77 lines -- one line to signal the start of the Update task against this database, 75 lines -- one for each view, and then a final line to denote the end of indexing in this database.
debug_nif=1
By far the most verbose way to collect information on indexing, debug_nif will write to a text file (which you specify using debug_outfile=c:\temp, for example). This can easily generate gigabytes of data per hour, so it should be used sparingly, if at all. The value of this debug variable is that it gives you the millisecond breakdown of all indexing activity, not just the Update task running every 15 minutes.
client_clock=1
Used on your client machine, not the server, this will write verbose information to a text file (which you specify using debug_outfile=c:\temp, for example), breaking down every client action you perform. This can be used to determine, for instance, whether or not a delay that the client sees is caused by long wait times for indexing.
To troubleshoot view indexing problems, start by collecting some data from log.nsf by setting log_update=1 (if not already set) and allow the server to collect information on view updates for a day. Then review the log.nsf Miscellaneous Events view for that day and look for patterns. Some meaningful patterns that may emerge are:
1- Very long update times for a specific database. This may indicate that the database has too much data being updated, too many complex views, or time/date-sensitive views (if the server is release 5 or earlier). The logical next step is to examine the business use and design of that database and perhaps to use log_update=2 for a day to pinpoint which views are problematic in that database.
2- Very long update cycles. We’ve seen cycles that have lasted four to five hours, meaning that instead of passing through all modified databases every 15 minutes, the Update task may only do so two or three times every day. This may indicate general performance problems affecting all tasks, or it may indicate a very high user or data load on the server. The logical next step would be to assess the general state of the server and the business use on it.
Whenever you find long update times, it is helpful to note which other tasks are running concurrently and whether or not those tasks are behaving normally. It is also helpful to note if the slow indexing times are universal, only during business hours, or only during certain peak times, such as every two hours. It is rare that a single observation will give you all the information you need to solve your problems, but it usually puts you on the right path.
View performance testing
To test the performance of various features and ways of building a view, we created a database with 400,000 documents and ran a scheduled agent to update 4,000 documents every five minutes. We then built approximately 20 views, each with slightly different features, but each displaying all 400,000 documents, using five columns. We will list the details later, but the big picture looks like this:
1- The size of your view will correlate strongly with the time required to rebuild and refresh that view. If your view doubles in size, so too will the time to rebuild or refresh that view. So, for example, if you have a 100 MB database that you expect will double in size every six months, and if you find that indexing takes approximately 30 seconds now, then you should anticipate that indexing will be 60 seconds in six months, then 120 seconds six months later, and so on.
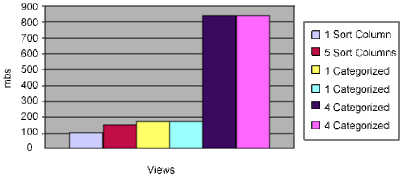
2- The biggest "performance killers" in terms of view indexing are categorized columns. Sort columns add a small amount of overhead as do some other features, such as the Generate unique keys option (more on this in the tips at the end of the article).
Figures 1 and 2 demonstrate both the relationship between size and refresh time and the significant overhead that categorized columns add to your view performance. Figure 1 plots view index size against response time.
Figure 1. View index size versus response times
And Figure 2 shows view size compared to refresh times.
Figure 2. View size versus refresh time
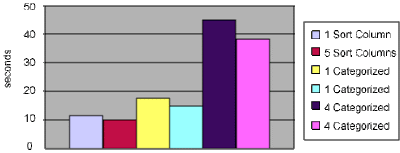
In both charts, the first and third categorized views are initially expanded, and the second and fourth views are initially collapsed. Collapsing your categorized views shows a small, but discernible savings in refresh time.
Reader Names fieldOver the past few years, we have seen a dramatic increase in the number of critical situations related to Reader Names fields and views. Customers find that performance is unacceptable frequently throughout the day. They cannot understand why because the code reviews and pilot tests all went smoothly. But a few months after rollout to their entire department/division/company, they find that complaints about performance are dominating conversations with their employees, and something has to be done.
ExamplesOur favorite examples are HR and Sales Force applications -- both of which typically have stringent Reader Names controls. The following table illustrates a hypothetical scenario for a company using a database of 400,000 documents.
| Title/role | Number of documents user can see (out of 400,000) | Percent of database |
| Corporate HQ, CEO, CIO, Domino administrators, developers | 400,000 | 100 percent |
| District Manager | 4,000 | 1 percent |
| Manager | 400 | 0.1 percent |
| Employee | 40 | 0.01 percent |
Upper management and the Domino administrators and developers typically experience pretty good performance, which makes the first reports of poor performance easy to ignore. Performance problems are typically exacerbated by weaker connectivity (WAN versus LAN), which may also make the early complaints seem invalid. But after some critical number of complaints have been registered, someone sits down at a workstation with an employee and sees just how long it takes to open the database or to save a document, and then the alarm bells start ringing. Figure 3 shows how long it took a user to open a view in the sample database with 400,000 documents. All views were already refreshed. No other activity was taking place on the test server, and only one user at a time was accessing the server.
Figure 3. Time required to open a view in the sample database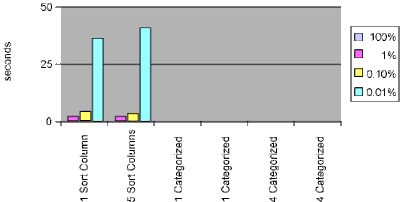
Users are denoted by the percentage of documents they can see. If you cannot see a bar, it means that it’s very close to zero.
Before moving on to an explanation of Reader Names fields and performance, we want to leave you with one thought about Figure 3: You can quickly see why users of the flat (sorted, not categorized) views would have such radically different impressions of the performance of this application if they were 0.01 percent users compared to 100 percent users.
Understanding Reader NamesWhen an application uses Reader Names, it means that some or all documents have Reader Names fields -- that is, fields that are Summary Read Access. Summary means that the data can be displayed in views. Technically, you can create Reader Names fields and prevent them from having the summary flag, but then Lotus Domino cannot properly ensure security of the documents at the view level. Read Access means just that -- who can see this document? Typically, individual names, group names, and [roles] populate these kinds of fields. We encourage the use of [roles] over groups whenever possible for reasons of maintenance and control, but in terms of performance, these are all equivalent.
When a user opens a view that contains these reader access controlled documents, the server has to determine whether or not this user is allowed to see each document. The server is very methodical, starting at the top and checking each document. The process is similar to the following:
1- Lotus Domino examines document #1, determines that the user can see it, and then displays it.
2- Lotus Domino examines document #2, determines that the user can see it, and then displays it.
3- Lotus Domino examines document #3, determines that the user cannot see it, and then hides the document from the user.
The process continues until Lotus Domino examines all documents in the view. Of course, the view has to be refreshed first, otherwise the server wouldn’t know which document was #1 or what its Reader Names values were. Let’s pause in this explanation to consider a classic example of poor performance. Imagine for a moment that our database is a Sales Tracking application, and it has a By Revenue view that is sorted in descending order by size of contract. Imagine that the view has five columns with the first two columns being sorted (for example, Revenue and SalesRep). There are no categories. In this case, when a user opens the view (a view that potentially displays 400,000 documents), this user forces a refresh first, if needed, and then the server starts with document #1 and checks to see whether or not that document can be displayed to the user, then it checks documents #2, #3, and so on.
You are presumably reading this article via a Web browser, and you’re perhaps familiar with the fact that browsers render portions of a page quickly (text) and other portions (such as graphics) more slowly. But a Domino server does not serve up views this way. It doesn’t send any portion of the view data to the user until it has what it considers a full screen of information. For practical purposes, this may be, for instance, 60 rows of data. You can test this yourself with a Notes client by opening a flat view (no categorized columns) and pressing the down arrow key. At first, the view scrolls quickly. Then there is a pause. This is when the server is dishing up another few KB of data for you. Then the view scrolls quickly again for another 60 or so rows. This repeats as long as you hold down the arrow key.
Back to our user: It turns out that he can see document #1, but perhaps he cannot see the next 10,000 documents. Why? Maybe he can see only 40 documents in the whole database. Because the Domino server is not going to show him anything until it can build about 60 rows of information (or until it gets all the way to the bottom of the view), it’s going to be a long wait.
This is exactly what users experience. They wait for minutes sometimes, while the server checks each document. In the case of a user who can see so few documents that they don’t fill the screen, the server goes through the entire view before sending the user the partial screen of data that he is allowed to see.
Some readers are aware of this functionality. Some are now screaming in pain. You can imagine that as someone who routinely analyzes applications for performance problems that this kind of problem would be one that we spot quickly and look to resolve with workarounds.
One workaround is to make the view categorized. The reason this helps performance is that the categories will always be displayed, and they take up a row of data. So in our example of a view By Revenue, the user would quickly see dozens of categories displaying, say, Revenue and SalesRep. Clicking the twistie to open any category results in a quick round trip to the server to determine that the underlying document is not viewable for this user, but that’s a far cry from having to examine 400,000 documents in one go.
On the other hand, finding that virtually every twistie the user clicks expands, but doesn’t show any documents, may be frustrating. In our example, there are some other possible workarounds, but we would assert that a view showing all documents by revenue is probably not a view that users with access to only 0.01 percent of the database should have access to. It is a contradiction of their access. But there are many cases in which it makes business sense to have many users accessing a view that contains more data than they should see. At the bottom of this section, we list some tips for building fast views in databases with reader access controlled documents.
We have two closing thoughts about Reader Names and views. First, in a normal production environment, it’s rare to get such clear data as we have in Figure 3. You’re much more likely to see that the performance problems caused by Reader Names cause a host of other performance delays, such as agents, view indexing, and so on. These problems may cause other problems. For example, you may notice that the views are slow for everyone and deduce that the problem is view indexing -- when the underlying problem is that Reader Names are forcing long computations by the server when some users open views.
Second, our tests (and Figure 3) represent an absolutely best-case scenario. The reason is that we had only one user at a time. We could duplicate the volume of data and even indexing issues with our scheduled agents, but our tests could not show the spiraling performance problem that occurs when hundreds of users simultaneously try to access views with reader access controlled documents. If your application uses Reader Names, you absolutely have to pay attention to view performance if you want to avoid a crisis.
Performance enhancing tips with reader access controlled documentsThe following are some tips for making applications/views that perform well even with reader access controlled documents:
1- Embedded view using Show Single Category. This is the winner, hands down. If your data is structured so that users can see all the documents in a category, then you can display just the contents of that category very quickly to the user. In some cases, it may make sense to let the user switch categories, in which case you have to consider whether or not he can see the contents of the other categories. But in most cases, the view would be something like My Sales and would show all the sales documents for the current user. The caveat for this kind of view is that the user interface for the Notes client is not quite as nice as the native view display. For Web browsers, it is just as good, and we have never seen a reason not to use this kind of view for Web browser applications. In fact, the performance is so good that it’s faster to open one of these with reader access controlled documents than to open a native view without reader access controlled documents!
2- Local Replicas. For a sales tracking database, many companies use local replication to ensure that their sales reps can use the database when disconnected. This is a great solution in many ways, but reader access controlled documents can be tricky when their Reader Names values change, and they need to disappear from some local replicas and appear on others.
3- Shared, Private on first use views. This is an elegant solution for Notes clients, but there are some drawbacks. First, it cannot be used for browsers. Second, the views need either to be stored locally, which can be problematic for some customers, or on the server, which can be a performance and maintenance problem of its own. Third, as the design of the application changes, it can be tricky updating the design of these (now) private views. And fourth, some customers have experienced performance problems, which may be related to having large numbers of these private views being created and used.
4- Categorized views. As seen in Figure 3, categorized views can be very fast to open with respect to Reader Names. They are bigger and slower to index, but typically they eliminate the Reader Names performance issue. The real caveat here is that users may find these views to be unfriendly, a label no one wants to have on their application.
The final tip concerns something to avoid. The feature "Don’t show empty categories" could, in theory, be used very successfully with the preceding tip to make a categorized view that would only display the categories containing documents that a user can see. However, in practice, it will result in a view with performance characteristics akin to a flat view, so it is probably a feature to avoid if performance is important.
General view performance tipsHere are some tips about view performance, regardless of whether or not reader access controlled documents are present.
Time/date formulasUsing @Now or @Today in a column or selection formula forces a view rebuild every time the view is refreshed. Therefore, if you use this kind of formula, consider making the view refresh Manually or "Auto, at most every n hours." That way, when users open the view, they will not have to wait for a view rebuild (or rarely so, in the latter case). The downside to this is that the view may be out-of-date because it opened without trying to refresh. Consider the contents of these views and how fast they change to determine whether or not you can use these indexing options safely.
Use click-sort judiciouslyClick-sort is a brilliant feature, one that we use in most public views in our applications. But it’s worth checking your hidden lookup views to be sure that no columns have click-sort enabled because having it increases the disk space and indexing requirements without adding any functionality for your users. On this same topic, consider using ascending or descending, but not both, when you use this feature to save on disk space and indexing time without impairing functionality. We would argue that the functionality is preferable when there is only one arrow because it is an on-off toggle rather than a three-way toggle.
Generate unique keys in indexOne of the lesser known performance enhancing features, the "Generate unique keys in index" option for lookup views can dramatically improve lookup times. When selected, the view discards all duplicate entries. For example, if you have 400,000 documents all displaying only CompanyName, and there are only 1,000 unique company names, then selecting this feature results in only the first document for each company being held in the view index. Although there is a slight overhead to this feature, it is easily outweighed by the fact that your view may dramatically decrease in size. One warning is that if you are displaying the results of a multi-value field, you need to use a code trick to avoid losing data.
For example, imagine a database has 100,000 documents, all containing a multi-value field called Industry. You want to look up a unique list of industries already selected so that the Industry drop-down list can display the values when users create new documents. If you use this unique keys feature in a view that has a single column displaying Industry, it is possible that a new document containing the values Automotive and Air would not display because another document containing Automotive was already being displayed in the view. Thus, your new value of Air would never be picked up by the lookup formula.
To avoid this problem, use a formula such as @Implode(Industry; "~") in the column formula, and then the drop-down field lookup formula may be @Explode(@DbColumn("Notes"; ""; "(LookupViewName)"; 1); "~"). Although you will have some minor duplication of data in your view, you will be guaranteed no data loss.
Color profilesIf you use color profiles (as in the mail template), then any change to that color profile document necessitates a view rebuild for any views that reference that color profile.
Default viewWhenever your application is opened, your default view is opened. Always be sure that this is a view that opens quickly. An interesting example of this is your mail file. For many users, the view that opens by default is the Inbox (folder). If a user is not in the habit of cleaning out her Inbox and if it has many thousands of documents, then it will be slower to open her mail file than if she regularly cleaned out her Inbox and if the view/folder had only dozens or hundreds of documents. Incidentally, this is why some companies have a policy that old documents in the Inbox are deleted periodically. It forces users to move those documents into other folders, thus improving performance both for that user and the server.
ConclusionThe conclusion we hope you draw from this article series is that application performance is something you can influence. With thoughtful application of common sense (and perhaps some of the information and tips in this article), you can keep the performance of your applications at a level that is more than acceptable for your users.
By : IBM






























